火车采集器V9入门之网址采集 实例讲解
采集网址的目的是进一步通过网址进入内容页,并将内容采集下来。在火车采集器中,为了获取网址而设置的规则称之为网址采集规则,也是正式实施采集的第一步。在此之前,我们需要学习几个专业术语:
起始网址:用来获取下级链接地址的入口网址,可以为一条或多条,可以通过添加起始网址向导添加同格式多条网址或导入文本网址。如果没有定义多级网址的获取方法,这些地址即作为内容页网址进行内容采集。
多级网址:依次根据列表里面的多级网址顺序采集分析地址,通过依次采集分析到最后一级得到内容页地址。多级网址的获取可以使用页面自动分析和手动获取的方法采集下级网址,在采集的过程中,可以同时采集列表分页及提取列表页附加参数。
分页:列表或内容页面较长,分成多个页面显示,采集时需要将所有子页的内容组合起来,这样的子页面就是分页(列表分页或内容分页)。
[参数]:用来匹配某项准备提取信息的标记标签,比如想要在代码中提取组合出某种格式。
代码"mClk(this,'108484','134217' );"就可以计作"mClk(this,'[参数]','[参数]'); ",按照次序,108484参数就是参数1,依次类推。
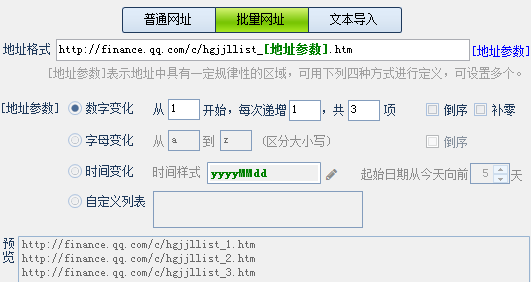
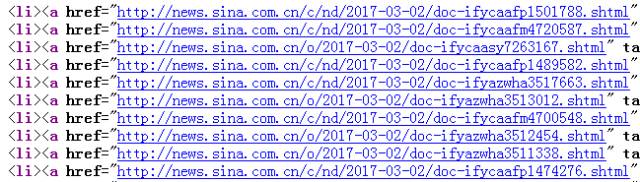
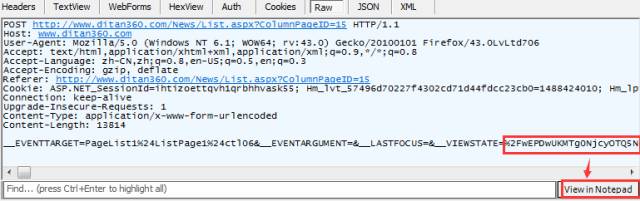
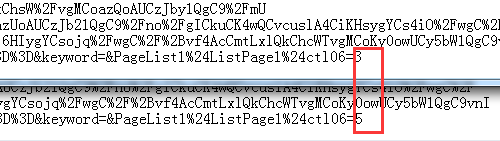
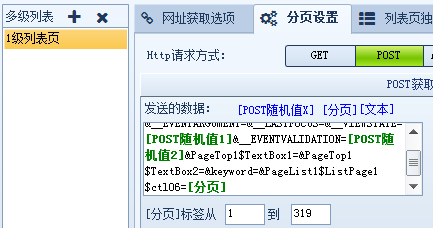
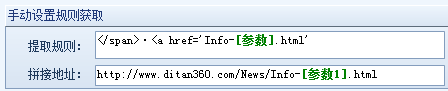
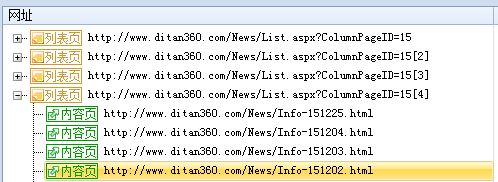
网址采集的第一步是写入起始网址,起始网址的写入方式有三种,这部分很容易上手: ①普通网址:手动输入单条或多条网址URL(一行一个,以http://或https://开头)。 ②批量网址:以通用的表达式批量生成网址。可对有规律性数字变化的网址匹配数字递增表达式,请看预览~ ③文本导入:将文本中的网址导入采集器中,文本中网址需为一行一个。 写完起始网址,我们重点讲后面的几种情况 情况1:起始网址就是内容页网址 这种情况下,我们只需把网址写进采集器即可,不再获取下一级网址了。选择起始网址就是内容页网址后,无需再做其他设置。 情况2:起始网址还需获取下一级,甚至多级才能得到内容页网址。 2/1 常规模式:起始网址下级就是内容页网址,我们从源代码中获取内容网址即可。 2/2 高级模式:起始网址下有多级,或其他情况。这里我们以中国低碳网为例,该网站有许多可作为典型讲解的案例。 如上图,起始网址下有列表页,且列表页很长,是以分页展示的。获取全部列表页才能获取全部内容页,所以我们先获取到列表分页的地址。 但在我们点击下一页的过程中发现,分页内容虽然变化了,但是网址却没变。 这时就需要用fiddler抓包工具分析数据,以POST方式获取分页地址。(后面小采会单独为大家介绍抓包,这里不细致的讲,大家可以在官网搜教程了解) 打开抓包工具后,我们一定要先清空,然后仅刷新该网站,再分别对第三页和第五页进行抓包(记得清空),查看raw 栏(这里还有cookie等我们能用到的数据),最后一行就是我们需要的内容,通过 “view in notepad”按钮将数据保存在记事本中方便对比查看,我们在数据最后分别看到了3和5,那么在火车采集器里,这个部分就记为【分页】标签。 我们可以看到,在抓包数据中除了分页的参数外还有很多别的参数,这就是POST随机值(这个值是为了解决浏览器的缓存问题,使每次打开页面都获取服务器最新的数据)所以我们也需要把这个值提取出来。 这个值的提取方法是:在页面源代码中找到该值的前后字符串。 到这里分页获取已经设置完成了,在分页里,如何获取内容网址呢?我们打开某一页的源代码,看看内容网址有什么特点。 很明显,这里的内容页网址是不完整的,我们必须把它拼凑成一个完成的网址,所以我们在网址获取选项中选择手动设置: 如下图从页面提取网址参数后按照内容页网址进行格式拼接。 到这里,该网站网址采集的全部规则已经设置完成了,我们来测试一下吧~ 列表页ok,内容页ok,测试没问题就进行保存,网址嗖嗖采起来~