火车采集器V9入门之内容采集 实例讲解
开始学习内容采集之前先了解下专业术语:
标签:标签是我们需要采集的内容类别,比如:标题、正文、作者……我们通过一个标签对同一类采集内容进行通用的规则设置。
(*):火车采集器中变量的通用符号,如果我们只需要知道这个变量的变化规律,而不需要关心这个变量到底是什么,这时就可使用这个符号代替。
多页:有些情况下,需要采集一个页面对应的网址,图片等内容时,需要另外打开一个新的页面才能采集到这些信息,这些另外打开的页面则称为多页。
我们以中国低碳网为例,我们打开一篇文章看看需要哪些字段

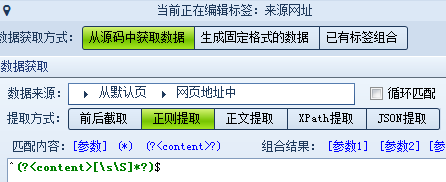
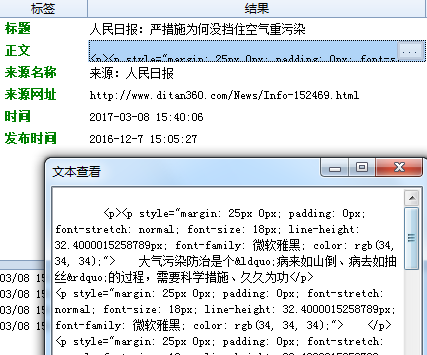
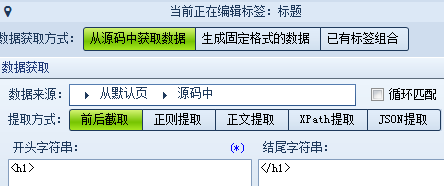
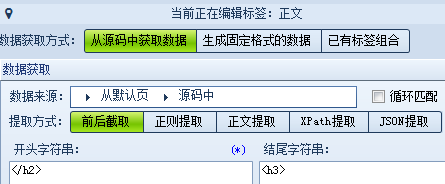
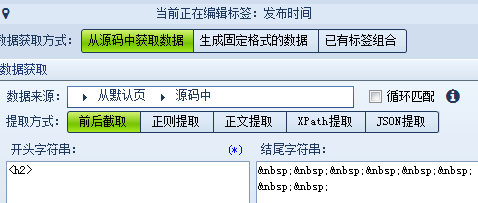
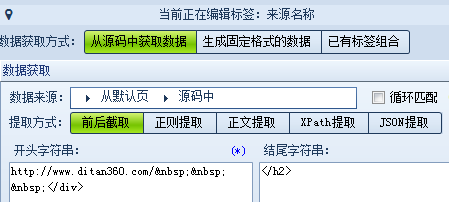
这样就可以确定我们需要设置的标签有:标题、时间、正文、来源等,我们逐个设置。 标题:打开网页源代码,找到标题的前后唯一字符串,使用前后截取的方式获取数据。(不一定只用一种方式,可以灵活选择,多打开几页查看一下是否相同) 正文: 前字符串: 后字符串: 时间:我们可以把原文的发布时间采集下来,也可以自行生成当前的时间,以便发布时使用。 分别设置如下 来源: 为什么前字符串不是</div>?查找可以发现,这并不是唯一字符串,如果填写</div> 来源网址:在采集的同时如果需要保存页面地址该怎么操作呢?源代码中并没有地址,这里就需要从网页地址中采取正则提取的方式。 (?<content>[\s\S]*?) 里的 [\s\S]*? 的意思就是匹配任意字符,并返回结果的意思。 而^和$分别代表:“匹配输入字符串开始的位置”和“匹配输入字符串结尾的位置” ,你们get了吗?(正则语法小白们可以点此学习一下) 所有的标签都完成后我们来测试一下。 可以看到正文里有很多不需要的链接和字符,重新回到标签编辑,对正文进行一些处理: 再测试一次,ok啦,我们还可以多换几个页面测试下,如果都没有问题就可以保存规则,嗖嗖嗖内容采起来~




会影响采集结果。