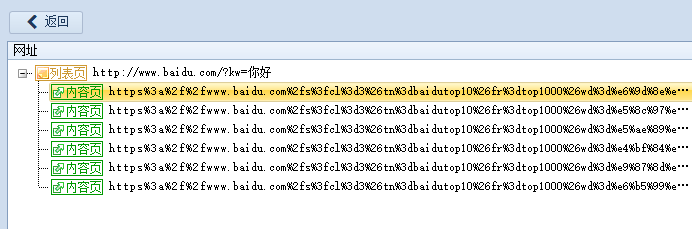
V9.11-列表页新增“地址处理”功能
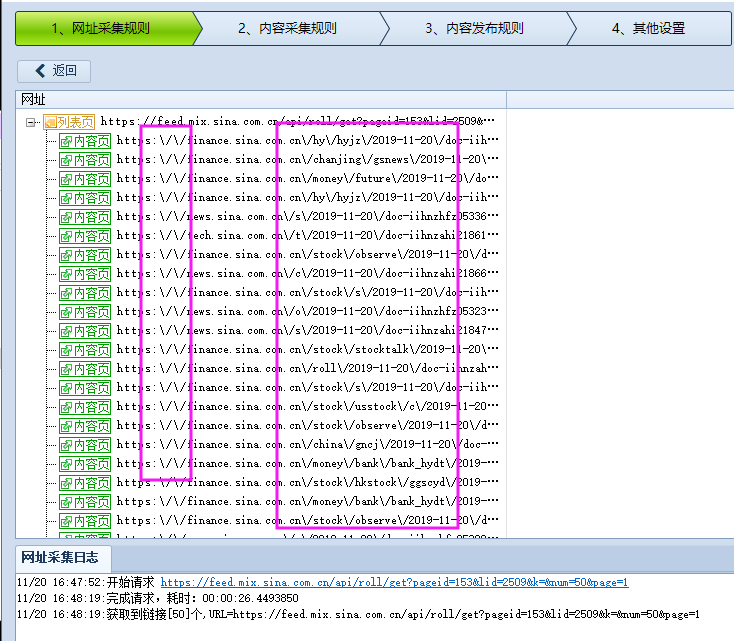
示例网址,新浪滚动新闻:https://news.sina.com.cn/roll/#pageid=153&lid=2509&k=&num=50&page=1
点击下一页,抓包可获取真实地址:
https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=1
分析json数据可以得知 url 后面的是内容页网址,设置如下:
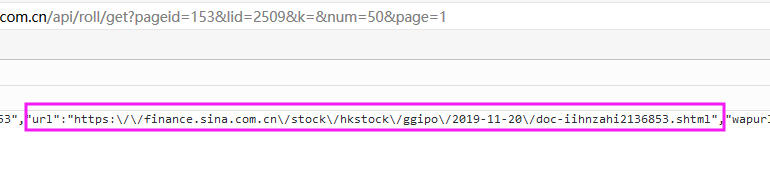
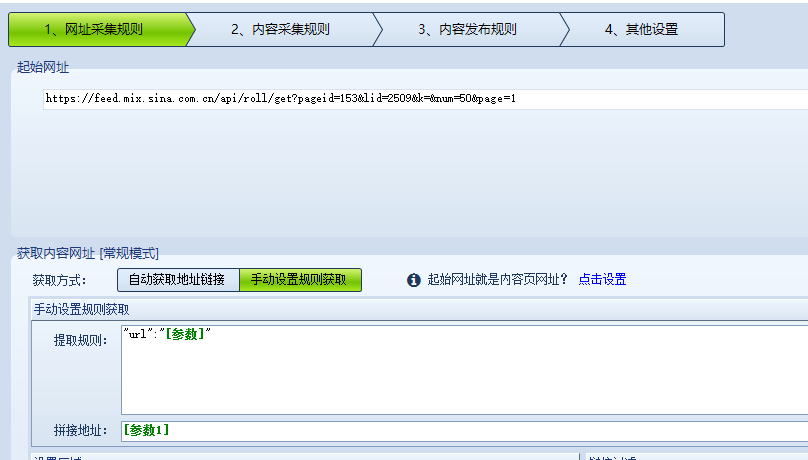
此网址采集需要设置头信息 Referer: https://news.sina.com.cn/roll/ 。头信息的获取可以参考此教程:点此跳转>>
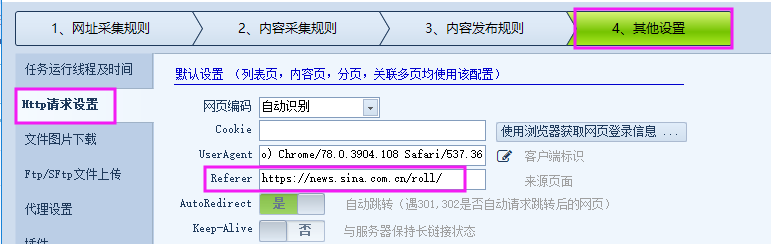
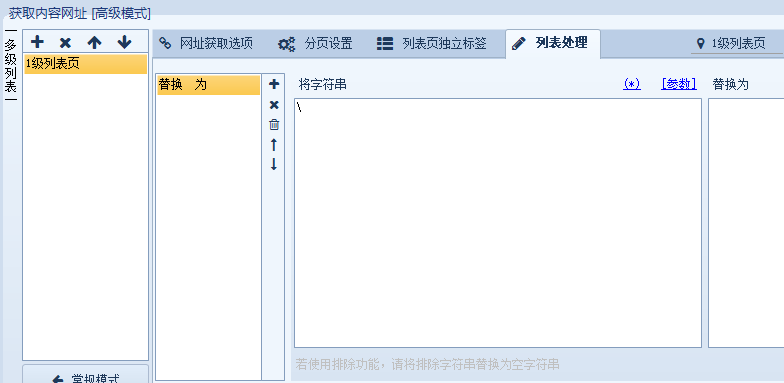
可以看到采集的网址里有很多 \ ,导致网址无法访问,而且网址不规则,不易处理。
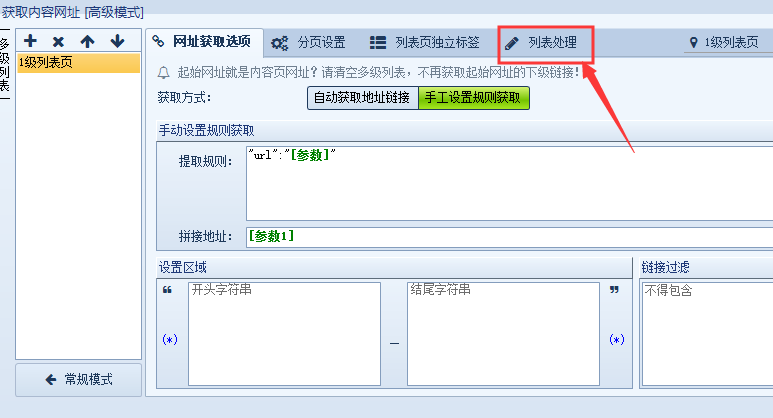
这种可以使用新增的“地址处理”功能
1. 内容替换/排重
可以对网址中内容进行替换,且替换完成后,重复的网址会自动去重。

2. 纯正则替换
可以使用正则表达式进行匹配,和内容替换功能类似
3. 字符编码处理
网址中有需要转码的内容,比如采到的链接里有 & 可以进行解码
https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=1
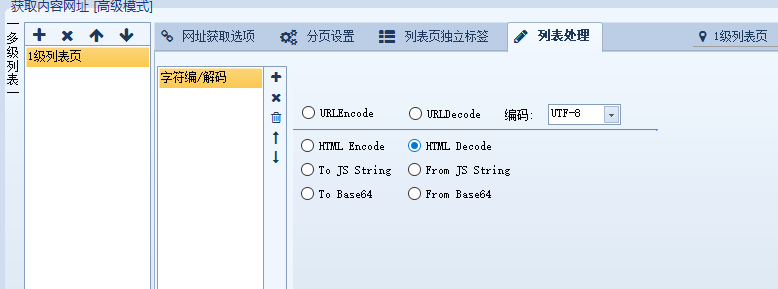
对于网址中有中文需要转码后才能访问的,也可以在这里设置,比如
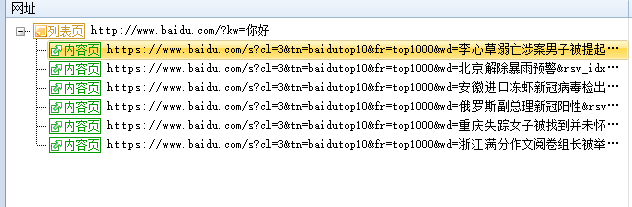
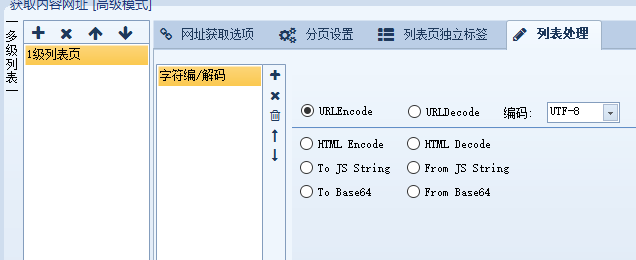
但是,只是这样设置我们会发现网址中的 : / & ? = 这些也被转码了,导致网址无法访问,所以需要再设置内容替换,把这些字符替换回去。